Documenting an IT infrastructure is essential to maintaining a reliable, secure and effective IT environment. Without proper documentation, valuable knowledge about the IT infrastructure can be lost when systems managers leave the organization. Documenting preserves this knowledge and allows it to be transferred to new team members.
Documentation shows how an infrastructure is configured and how it is supposed to work, which helps with troubleshooting and maintenance tasks. And in the event of a disaster, documentation helps ensuring that the infrastructure can be restored to its previous state as quickly as possiible.
CMDB
The most basic form of documentation is having an inventory of all hardware, software, and networking components in the infrastructure. Often this inventory is stored in a Configuration Management Database (CMDB).
A CMDB should include the make and model of each component, as well as its location and function. Many CMDB tools provide the ability to correlate components, such as all the components needed to run an application. This can be very helpful when making changes or finding the root cause of an application failure.
Since the CMDB is needed as a basis for ITIL processes, it should be kept up to date as much as possible, using automated tools if possible.
Diagrams
A visual representation of the infrastructure can help a lot in understanding its topology. A topology diagram shows the relationships between different components and how they are connected.
There is no widely accepted formal standard for documenting IT infrastructures. Often Microsoft Visio or Diagrams.net diagrams are used to provide an overview of parts of the infrastructure, usually the network configuration and groups of servers. Although these diagrams necessarily omit many details, they can provide a general overview of the entire environment in one view.
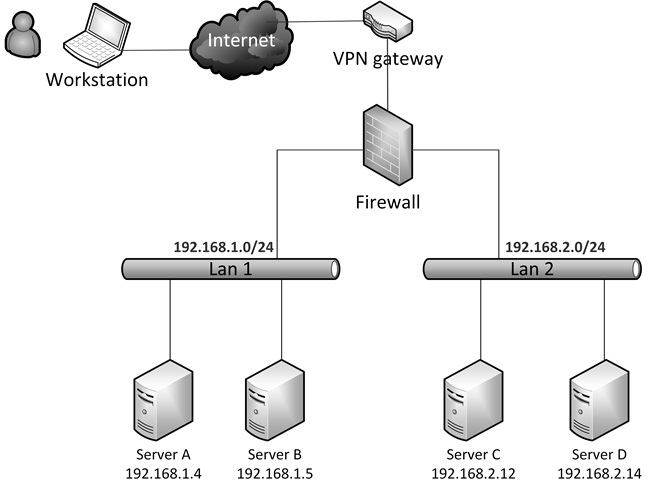
Tools such as Visio and Diagrams.net provide a comprehensive set of templates for infrastructure components, including servers, routers, firewalls, and components of public cloud environments.

The Enterprise Architecture modeling language ArchiMate includes a technical layer that can also be used to document infrastructures. ArchiMate is not an optimal way to document infrastructure, as it is designed to capture high-level concepts and relationships, rather than the detailed technical specifications that are important for documenting IT infrastructures. Also, ArchiMate is a complex modeling language that takes a lot of time and effort to learn and use effectively.
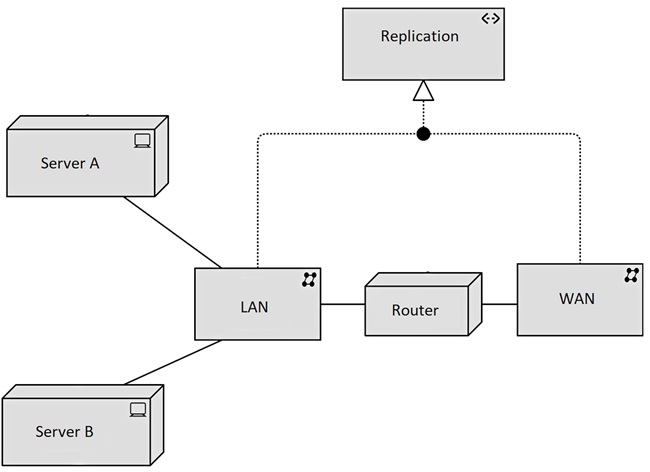
Please remember that pictures should always be explained to prevent readers from interpreting them themselves. Therefore, it is best to include the pictures in a document or (preferably) and set of wiki web pages in which the pictures are explained step by step. And it is important that this documentation, including the explanations, be updated with every change in the infrastructure.
IaC tools
Automation tools, such as IaC and configuration management tools can be used as a way to document how the infrastructure is built and the reason behind certain decisions. An important advantage of this method of documentation is that it can be done during modifications to the IaC code. For any future changes, the documentation in the code can easily be updated immediately.
A disadvantage is that the code must be read to get an understanding of the architecture of the infrastructure. It does not provide you with an instant overview of the setup, like diagrams do.
Below is an example of documentation in a Terraform code snippet.
############################################################
# This VM is needed to run the web server
############################################################
Resource "azurerm_windows_virtual_machine" "example" {
name = "myvm1"
location = "northeurope"
resource_group_name = "MyRG"
network_interface_ids = [ azurerm_network_interface.myvm 1 nic.id ]
size = "Standard_B1s"
admin_username = "adminuser"
admin_password = "Password123!"
############################################################
# The server must run the Windows Datacenter version
# to ensure it is compatible with the application libraries
############################################################
source_image_reference {
publisher = "MicrosoftWindowsServer"
offer = "WindowsServer"
sku = "2019-Datacenter"
version = "latest"
}
os_disk {
caching = "ReadWrite"
storage_account_type = "Standard_LRS"
}
}
Documenting procedures
At a minimum, written procedural documentation should include:
- Procedures for routine tasks, such as software updates
- An Infrastructure naming convention that describes how infrastructure components should be named
- An IP addressing plan that shows how IP addresses are distributed to devices based on the network architecture.
- A DNS naming convention that describes how DNS records should be named in the various network segments, such as internal DTAP segments and the DMZ.
- A fallback procedure that describes how to perform a fallback of the infrastructure to the secondary datacenter.
- A disaster recovery plan.
- Backup and recovery procedures.
Documentation should be updated regularly as changes are made to the infrastructure.
This entry was posted on Tuesday 16 December 2025
IT FinOps, also known as Financial Operations for IT, focuses on managing and optimizing the financial aspects of IT operations. The goal of IT FinOps is to maximize the value of IT investments and reduce unnecessary costs.
IT FinOps teams monitor costs, analyze usage patterns, identify inefficiencies and implement cost-saving measures. An IT FinOps team works with other disciplines such as finance, procurement, and operations to ensure that all IT spending is accounted for and optimized.
IT FinOps becomes even more important when moving to the public cloud, which can introduce complex cost structures. In a cloud environment, pay-as-you-go is the standard. However, most cloud providers also offer discounts if a certain number of resources are reserved in advance for an extended period of time. The types of charges can vary widely. For example, for a VM, you pay per second the VM is up; for a network connection, you pay for the number of bytes sent and received; and for storage, you pay for the amount of storage, the storage tier, and the number of reads and writes.
This entry was posted on Thursday 27 November 2025
There are a number of scenarios that can be used to put the new infrastructure in production as the replacement for an existing system – to “Go Live”:
- Big Bang – In the big bang scenario, at a set time, the existing system is switched off and the new system is immediately put in production, possibly after a short data migration run. This is the riskiest scenario because it may be impossible to roll back to the old system after the system is live for some time, and because downtime can occur when something goes wrong during the switchover.
- Parallel changeover – In this scenario, both the new and the existing system run simultaneously for some time (typically weeks). This allows for testing the new system on both functionality and non-functional attributes, and ensuring it works with live production data before switching off the existing system. As both systems are running and processing data, switching back is possible at any time, minimizing risk. A big disadvantage of this scenario is the cost of maintaining both systems and the possible extra work to keep both systems in sync. Also, many system designs don’t allow running two systems in parallel, for instance, if the system has many interfaces with other systems.
- Phased changeover – In a phased scenario, individual components or functionalities of the existing system are taken over by the new system, one by one. This reduces risk, as the changeover can be done gradually and controlled. This scenario can be quite costly, since typically many interfaces between the existing and the new system must be created and maintained. These new interfaces introduce new risk to the scenario, as they must be tested extensively and could fail in production. Also, the existing system must be kept online until the last component or functionality is moved to the new system, which can take considerable time and can lead to high cost.
While in theory a big bang scenario has the highest risk, in practice, it is most often used, as the scenario is the least complex to execute, and because the risk is limited to the changeover moment, when the project team is at full strength and ready to jump in if anything fails.
The go-live should be very well prepared. After the go-live scenario is determined, a step-by-step plan must be created describing each step in the scenario in detail. This plan must be reviewed, tested and improved multiple times, well in advance of the go-live date to eliminate possible surprises and to minimize risk. The scenario should include intermediate tests and multiple “go/no go” milestones, where the go-live can be aborted if anything unexpected happens. The plan should also have a defined point of no return – a go decision at this point means there is no way back to the old system. Either because there is no time left to move back to the original situation, or because an irreversible step is taken (like an update of a critical data model).
At the go-live date, high alert is needed from the project team and from the systems managers, service desk and senior management to be able to fix any issues that might arise.
After the new system is live, on-site support should be available for a predetermined time to resolve problems that may arise after the system is live; problems for which the service desk cannot yet be responsible.
This entry was posted on Thursday 06 November 2025
Where IaC defines infrastructure components, configuration management tools define the configuration of those infrastructure components. For example, a VM can be deployed using IaC, but the software that runs on that VM, or its operating system parameters, must be configured afterwards. This is a job for configuration management tools. Configuration management also uses declarative languages that define the desired state of the configuration.
The most used configuration management tools are Ansible, Puppet, and Chef.
Ansible uses YAML playbooks to define resources and can be used to automate server provisioning, configuration management, application deployment, and more. Ansible is agentless and can be used to manage a wide range of platforms, including cloud and on-premises servers.
As an example, the following Ansible playbook creates a httpd webserver on a Linux server:
- name: Install httpd
hosts: webserver
become: yes
tasks:
- name: Install httpd package
yum:
name: httpd
state: present
- name: Start httpd service
service:
name: httpd
state: started
enabled: yes
Puppet is a configuration management tool that can be used to manage servers, networks, storage, and more. The following Puppet manifest creates a httpd webserver on a Linux server:
# Install httpd package
package { 'httpd':
ensure => 'installed',
}
# Start httpd service
service { 'httpd':
ensure => 'running',
enable => true,
}
Chef is another configuration management tool. It uses a domain-specific language called Ruby to define infrastructure resources and provides features like idempotency, versioning, and testing. Chef can be used to manage servers, networks, storage, and more.
The following Chef recipe creates a httpd webserver on a Linux server:
# Install Apache HTTP Server (httpd) package
package 'httpd' do
action :install
end
# Start and enable httpd service
service 'httpd' do
action [:start, :enable]
end
Configuration management tools are often run periodically, for instance every few hours, to ensure any manual change to the deployed environment is reverted to the state as defined in the configuration management tool.
This entry was posted on Wednesday 01 October 2025
There are several commonly used IaC languages. Below are some of the most popular ones.
Terraform is a popular open-source tool and Domain-Specific Language (DSL) for building, changing, and versioning infrastructure. Terraform is cloud agnostic, which means that it has a generic syntax can be used to configure a wide range of cloud providers and infrastructure platforms, including AWS, Azure, GCP, Kubernetes, Red Hat OpenShift, databases like MySQL and PostgreSQL, firewalls, and more. But it must be noted that each platform needs its own configuration details – in Terraform, configuring an EC2 VM in AWS is done differently than configuring a VM in Azure.
As an example, the following Terraform code creates a virtual machine in Azure:
Resource "azurerm_network_interface" "mynic" {
name = "myvm1-nic"
location = "northeurope"
resource_group_name = "MyRG"
ip_configuration {
name = "ipconfig1"
subnet_id = azurerm_subnet.frontendsubnet.id
private_ip_address_allocation = "Dynamic"
}
}
Resource "azurerm_windows_virtual_machine" "example" {
name = "myvm1"
location = "northeurope"
resource_group_name = "MyRG"
network_interface_ids = [azurerm_network_interface.mynic.id]
size = "Standard_B1s"
admin_username = "adminuser"
admin_password = "Password123!"
source_image_reference {
publisher = "MicrosoftWindowsServer"
offer = "WindowsServer"
sku = "2019-Datacenter"
version = "latest"
}
os_disk {
caching = "ReadWrite"
storage_account_type = "Standard_LRS"
}
}
As a comparison, the following Terraform code creates an EC2 virtual machine in AWS:
resource "aws_instance" "example" {
ami = "ami-0be2609ba883822ec" # Windows Server 2019 Base
instance_type = "t2.micro"
key_name = "my_keypair"
vpc_security_group_ids = [aws_security_group.allow_rdp.id]
subnet_id = "subnet-12345678"
associate_public_ip_address = true
private_ip = "10.0.1.10" # Private IP address of the instance
user_data = <<-EOF
<powershell>
# Set the administrator password
net user Administrator <password>
</powershell>
EOF
}
}
As you can see, the syntax is the same, but the way the virtual machine is created is different between the cloud providers.
Azure Resource Manager (ARM) templates are JSON files that describe Azure infrastructure resources. ARM templates provide a declarative syntax for defining the infrastructure resources and their dependencies, as well as the configuration settings for each resource.
Azure Bicep is a Domain-Specific Language (DSL) for Microsoft Azure. Bicep builds on top of ARM templates and provides an abstraction layer that allows developers to write code that is easier to read and write than ARM templates. Bicep supports the same resources and functionality as ARM templates, but with a more intuitive syntax, better error handling, and reusable modules.
The following Bicep script creates a virtual machine in Azure:
param location string = 'eastus'
param vmName string = 'myVm'
param adminUsername string = 'admin'
param adminPassword string = 'password'
resource vm 'Microsoft.Compute/virtualMachines@2021-04-01' = {
name: vmName
location: location
tags: {
environment: 'dev'
}
properties: {
hardwareProfile: {
vmSize: 'Standard_D2_v3'
}
storageProfile: {
imageReference: {
publisher: 'MicrosoftWindowsServer'
offer: 'WindowsServer'
sku: '2019-Datacenter'
version: 'latest'
}
osDisk: {
createOption: 'FromImage'
}
}
osProfile: {
computerName: vmName
adminUsername: adminUsername
adminPassword: adminPassword
}
networkProfile: {
networkInterfaces: [
{
id: resourceId('Microsoft.Network/networkInterfaces', '${vmName}-nic')
}
]
}
}
}
resource nic 'Microsoft.Network/networkInterfaces@2021-02-01' = {
name: '${vmName}-nic'
location: location
properties: {
ipConfigurations: [
{
name: 'ipconfig1'
properties: {
subnet: {
id: resourceId('Microsoft.Network/virtualNetworks/subnets', 'myVnet', 'default')
}
privateIPAllocationMethod: 'Dynamic'
}
}
]
}
}
Google Cloud Deployment Manager allows to define and manage GCP cloud infrastructures using YAML or Python templates. It is similar to Azure ARM templates. Google Cloud Deployment Manager defines and manages GCP resources, such as Compute Engine virtual machines, Google Kubernetes Engine clusters, Cloud Storage buckets, and Cloud SQL databases.
The following Cloud Deployment Manager YAML script creates a virtual machine in GCP:
resources:
- name: my-vm
type: compute.v1.instance
properties:
zone: us-central1-a
machineType: zones/us-central1-a/machineTypes/n1-standard-1
disks:
- deviceName: boot
type: PERSISTENT
boot: true
autoDelete: true
initializeParams:
sourceImage: projects/debian-cloud/global/images/family/ debian-10
networkInterfaces:
- network: global/networks/default
accessConfigs:
- name: External NAT
type: ONE_TO_ONE_NAT
AWS CloudFormation allows to define and manage AWS cloud infrastructures using JSON or YAML templates. It is similar to Azure Resource Manager (ARM) templates and Google Cloud Deployment Manager. CloudFormation can define and manage AWS resources, such as EC2 instances, S3 buckets, and RDS databases.
The following CloudFormation script creates an EC2 virtual machine in AWS:
AWSTemplateFormatVersion: '2010-09-09'
Resources:
EC2Instance:
Type: 'AWS::EC2::Instance'
Properties:
ImageId: 'ami-0c55b159cbfafe1f0' # Ubuntu 20.04 LTS
InstanceType: 't2.micro'
KeyName: 'my-key-pair'
NetworkInterfaces:
- GroupSet:
- 'sg-0123456789abcdef' # security group
AssociatePublicIpAddress: 'true'
DeviceIndex: '0'
DeleteOnTermination: 'true'
This entry was posted on Wednesday 30 April 2025
 Dutch
Dutch